Indsigt
Da machine learning blev hvermandseje

Indsigt

Digitaliseringsbølgen medfører en demokratisering af avancerede teknologier, som for eksempel betyder, at machine learning flytter ind overalt – både i vores mobiltelefoner, på sociale medier såvel som i rådgiverbranchen.
I dagligdagen er det de færreste, der tænker nærmere over mange af de meget avancerede teknologier og redskaber, vi gør brug af. Et eksempel er udbredelsen og anvendelsen af GIS-systemer og GIS-data. Der er sket en demokratisering, hvor en teknologi, der tidligere udelukkende var tilgængelig for en snæver gruppe eksperter, er blevet hvermandseje, let tilgængelig og bredt anvendt. I disse år sker det samme med machine learning, der som teknologi er modnet og har bevæget sig fra forskernes verden på universiteterne og ud i omverden. Vi ser i disse år teknologien blive implementeret og gøre gavn i stadigt flere typer rådgivningsydelser. Dette skaber nye muligheder og forandring.
I arbejdet med machine learning får vi stadigt større indsigt i betydningen af teknologien. Dels som et værdifuldt, nyt redskab i vores arbejde, men også i form af de følger teknologien vil få på selve måden, vi arbejder på i fremtiden og de perspektiver, der åbner sig for nye løsninger på gamle problemstillinger.
I det følgende vil vi berøre to udvalgte eksempler, hvor vi ikke fokuserer på teknikken, men den digitale forandringskraft teknikken forløser. Vi vil her demonstrere, hvordan vi vha. lige dele data, faglig indsigt og kode-teknisk snilde både kan effektivisere fysiske beregninger og skabe nye indsigter og forståelse samt spare penge ved at sammensætte mange forskellige typer data.

Figur 1: Beregning af påvirkning af flodsystem ved indvinding af grundvand. Venstre: Beregnet i Modflow; Midt: Beregnet vha. machine learning Neuralt Netværk; Højre: beregnet vha. machine learning i høj opløsning. Klik på billedet for at se det i større format.
I sit arbejde som Ph.d.-studerende ved afdelingen NIRAS DATA, der arbejder med softwareudvikling og data science på tværs af forsyningssektoren, forsker Mathias Dahl i anvendelsen af machine learning på grundvandsområdet. Han er dybt optaget af at kombinere hastigheden fra machine learning med de fysiske modellers præcision, og resultaterne er lovende.
Han eksperimenterer blandt andet med grundvandsmodeller. Billedet til venstre på figur 1 viser resultatet af en traditionel MODFLOW beregning af et flodsystems påvirkning ved en placering af en boring til grundvandsindvinding i hver pixel i billedet.
Vore modeller viser, at vi allerede nu med mere end 85% nøjagtighed kan genskabe de meget beregningstunge resultater, som de traditionelle metoder generere, på en brøkdel af tiden.
Mathias Dahl, Ph.d.-studerende
Billedet udgør et følsomhedskort, der kan bruges til placering af nye boringer, hvor man ikke ønsker at påvirke skrøbelige naturtyper. Billedet her tager mellem 10 og 15 timer at generere på en kraftig computer. Billedet i midten er genereret med et neuralt netværk. Dette kan genereres på under 1 sekund. Billedet længst til højre viser samme, blot i en meget finere og mere detaljeret opløsning. Resultaterne bliver bedre og bedre, og vi forventer at få resultater, der er fuldt sammenlignelige med de mere traditionelle modeller. Men det slutter ikke her.
Fænomenet, at udskifte traditionelle metoder til modelberegning med machine learning-baserede metoder, sker bredt på alle områder, hvor der arbejdes med modeller – og perspektiverne er store. Hastigheden og nøjagtigheden i de fysiske beregninger fra machine learning, som eksemplet ovenfor, gør det muligt at skabe en helt ny generation af interaktive softwareløsninger til beslutningsstøtte.
Med de hurtige beregningsmotorer i maskinrummet på disse nye løsninger, vil det blive muligt at eksperimentere langt mere interaktivt og legende. En realtidsberegning af grundvandspåvirkningen ved forskellige scenarier og løsninger af for eksempel separatkloakeringsprojekter, implementering af LAR-løsninger, vandindvinding osv. gør det pludselig muligt at afprøve og forkaste mange forskellige scenarier på stedet. Den direkte interaktivitet gør redskaberne mere tilgængelige, og i en ikke så fjern fremtid behøver man måske ikke nødvendigvis være hydrologisk ekspert for at anvende disse nye redskaber, men kan få værdi af den nye generation af redskaber i andre roller.
Uvedkommende vand (UV) er en kilde til merudgifter og belastning af kloaknettets kapacitet. Dette er en problemstilling det MUDP-støttede DRAINman projekt har stillet skarpt på i et samarbejde mellem Grundfos, DHI, Aarhus Vand, Wavin, Aarsleff, Aalborg Universitet og NIRAS.
En væsentlig kilde til UV er grundvand. Problemstilling omkring uvedkommende vand forværres af klimaforandringer og de følgende problemer med stigende grundvand kombineret med behov for kapacitetsudvidelser. Et eskalerende problem. Visionen i dette arbejde har været at sammenstille alle relevante, tilgængelige data og skabe beslutningsgrundlaget for at udpege de ledninger, der giver den økonomisk bedste rentabilitet at renovere. Med andre ord er målet at fjerne mest mulig grundvand fra ledningsnettet for pengene.
Det første skridt i dette arbejde var at etablere et mål for risikoen for uvedkommende vand for alle ledninger i ledningsnettet, et såkaldt UV-indeks. Som datagrundlag blev der gjort en ingeniørfaglig vurdering i udvælgelsen af observationstyper fra TV-inspektionsdata. Ved brug af machine learning algoritmerne Random Forrest og Baysian network blev der genereret risikokort for de enkelte observationstyper for hele ledningsnettet, hvor en lang række data blev anvendt for at underbygge ekstrapolationen inkl. blandt andet geologi, jordbund, hydrologi, trafikdata, ledningens atributter, vegetationsdata, osv.
De resulterende risikolag blev derefter kombineret i et endeligt mål for risiko for uvedkommende vand, UV-indeks.
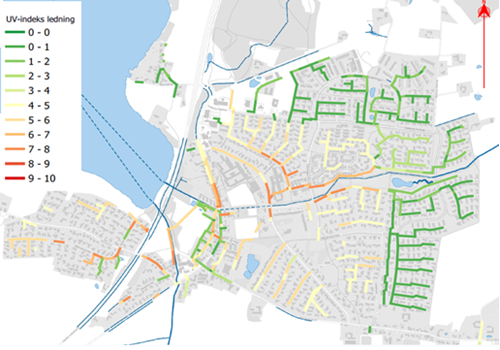
Figur 2: UV-Indeks i Solbjerg. Risiko for indsivning af uvedkommende grundvand. Data venligt udlånt af Aarhus Vand.
For videre at oparbejde viden blev dette kombineret med en analyse på pumpedata udført af AAU, der gav et mål for de totale mængder af uvedkommende grundvand i ledningsnettet. Med en fordelingsnøgle beregnet ud fra det længdevægtede UV-indeks, blev den totale mængde indsivning delt ud på hver enkelt ledning vist i figur 3. Endeligt blev de totale mængder og udgiften til at håndtere disse, sammenholdt med udgiften til at strømpefore de enkelte ledninger, hvilket gav et mål pr. ledning for tilbagebetalingstiden for investeringen i at strømpefore ledningen.
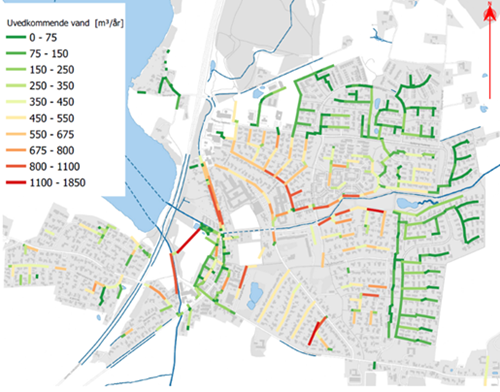
Figur 3: Grundvandsindsivning pr. ledningsstrækning pr. år. Data venligt udlånt af Aarhus Vand.
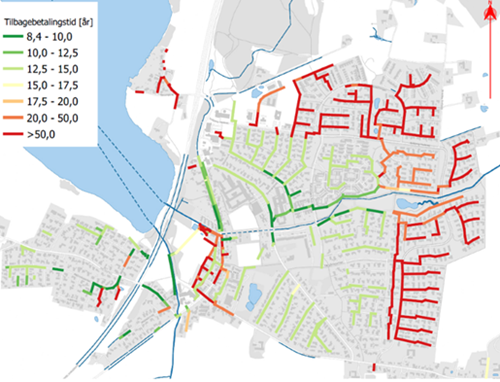
Figur 4: Tilbagebetalingstid for strømpeforing. Data venligt udlånt af Aarhus Vand.
Resultatet er vist i figur 4. Som det ses, findes den laveste tilbagebetalingstid generelt også i de ledninger, som har den højeste andel uvedkommende vand. Men nogle ledninger med stor mængde indsivning er på grund af længde eller diameter ikke så interessante at strømpefore, fordi tilbagebetalingstiden bliver meget høj. Resultatet kan anvendes til at finde de områder, hvor man indledningsvist får fjernet mest uvedkommende vand for pengene.
Eksemplet demonstrerer, hvordan vi ved at lade machine learning algoritmerne finde sammenhænge i data, der ikke er direkte genkendelige for det menneskelige øje, kan skabe et billede, der kombinerer mange datatyper og informationen i et samlet, overskueligt og letforståeligt billede. Når dette kombineres med vores faglighed, kan vi skabe ny indsigt, der gør det muligt at tage bedre beslutninger og – som i tilfældet her – også spare penge.
Den gamle Nokia 3210 var stabil, kompakt, robust, holdt strøm for evigt, kunne ringe og sende SMS’er. Fantastisk stykke teknologi, der fuldt leverede det, der var behovet. Hvem kunne have brug for mere? I dag er vore telefoner store, skrøbelige størrelser af glas, der er spækket med apps baseret på data og machine learning. Det er blevet en digital forlængelse af os selv og vores direkte opkobling til internettet og verden. Nokia har for længst forladt det mobilmarked, de dominerede i en årrække. Teknologien skaber nye muligheder, danner grundlaget for nye behov vi ikke kender i dag, og ændrer markeder. Machine learning er som en del af digitaliseringsbølgen en teknologi, der har kraften til at skabe en sådan omvæltning. Der skabes nye muligheder, hvilket danner nye behov, selvom vi måske kan tænke, at de metoder og redskaber vi arbejder med i dag, er fuldt tilstrækkelige og ikke kan blive bedre.
I det fremsynede diskussionsoplæg ”Fremtidens rådgiver” fra tænketanken for fremtidens rådgivning fra 2017, beskrives det marked og den fremtid, rådgiverbranchen ser ind i. En fremtid hvor digitaliseringen skaber grundlaget for udnyttelsen af globaliseringen, automatisering samt effektivisering, og ændrer rådgivningsmarkedet. Her beskrives, hvordan selve forretningsmodellen for rådgiveren ændrer sig fra måling på timer, til måling på output. Rådgivermarkedet deles i to hold; et digitaliseret A-hold der mestrer, opsøger og gør aktivt brug af digitalisering og globaliseringens muligheder, og et B-hold der alene på pris kæmper mod A-holdets automatiserede ydelser.
Den trend, der blev aflæst i 2017, har i dag fire år senere kun manifesteret sig yderligere. De digitale muligheder og deres følgevirkninger bliver stadigt tydeligere. Bolden ruller. Grib!

Mathias Busk Nielsen
Konsulent
Aarhus, Denmark
Mathias Busk Dahl er geofysiker fra Aarhus Universitet. I 2020 påbegyndte han sin erhvervs-ph.d. - et samarbejde mellem NIRAS og Aarhus Universitet (Institut for Geoscience og Institut for Datalogi). Mathias undersøger i sit forskningsprojekt, hvordan man kan reducere tidsforbruget ved grundvandsberegninger ved at kombinere machine learning, geostatistik og hydrologi. Det skal skabe et nyt state-of-the-art værktøj til de normalt tidskrævende beregningsmetoder.
Kontakt



